
Here is my latest tutorial
 Find a vulnerable website:
Find a vulnerable website:
Now Navigate To Folders Like Root ect



 To hack a website in most cases admin page is more important.I will show you a simple trick to find admin pages
To hack a website in most cases admin page is more important.I will show you a simple trick to find admin pages
I will use a simple loop hole in robots.txt
First select a website eg:www.google.com
Then after the address add /robots.txt to website adress
Now ur Url will be www.google.com/robots.txt
Now you will get a txt file showing all pages which is disallowed by admin to search engine
If the site admin is a good Administrator he will not allow admin page to be crawled by search engine
Now seach for admin you will find admin page
See bellow

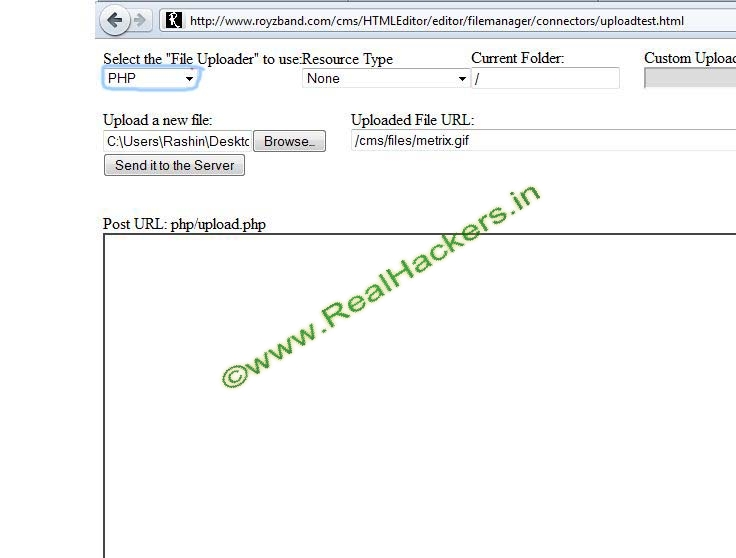
Durpal IMCE Website Defacing Exploit
Exploit Google Dork: inurl:"/imce?dir="
Now Navigate To Folders Like Root ect
Click Upload
Select A Html Or Php Deface Page
Select A Html Or Php Deface Page
Click Upload
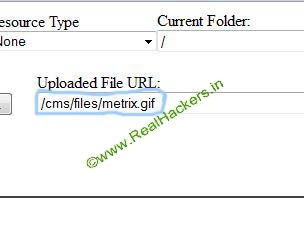
Now you can acess ur defaced page

Note:Some Sites May Only Accept .Jpg Or .Png Formats
Live Demo:
Enable Ftp In Windows 7

Ftp File Transfer Protocol is a protocol just like Tcp or Ip Which is used totransfer files between remote computers.Mainly used in web servers
Steps:
Open Computer
Go To Bellow Address
Control Panel\Programs Click Turn Windows Function On Or OffGo To Internet Information Services

Double Click To Get Ftp Server
Check Ftp Server Click Ok

Using Ftp:
To use ftp go to Command Promt and enter query FTP
To connect to a server: open domainname/ip eg:open 192.152.132.61
To Login use bellow commands: User (X:(none)): username Replace username with your username
Commands:
! delete literal prompt send
? debug ls put status
append dir mdelete pwd trace
ascii disconnect mdir quit type
bell get mget quote user
binary glob mkdir recv verbose
bye hash mls remotehelp
cd help mput rename
close lcd open rmdir
Note:This Is Just An Introduction To Brute Force Attacks And Web Defacing Using Anonymous FtpFind Admin Page Of A Website The Simple Methord
 To hack a website in most cases admin page is more important.I will show you a simple trick to find admin pages
To hack a website in most cases admin page is more important.I will show you a simple trick to find admin pagesI will use a simple loop hole in robots.txt
Do you know about robots.txt file ?
Yes it is file to spiders of search engines to decide what to crawl and what not to crawl. The Robot Exclusion Standard, also known as the Robots Exclusion Protocol or robots.txt protocol, is a convention to prevent cooperating web crawlers and other web robots from accessing all or part of a website
Yes lets start:
First select a website eg:www.google.com
Then after the address add /robots.txt to website adress
Now ur Url will be www.google.com/robots.txt
Now you will get a txt file showing all pages which is disallowed by admin to search engine
If the site admin is a good Administrator he will not allow admin page to be crawled by search engine
Now seach for admin you will find admin page
See bellow




















{kind=link}
No comments :
Post a Comment